Vibe testing with Playwright



I have been using Playwright for some time now, and I think it's the best tool for end-to-end testing.
Playwright is fast, reliable, and has a great and intuitive API.
It also has a great Developer Experience, for example, it's easy to automate the writing process of your tests using the codegen command. With codegen, it records your actions and generates the test code in the background while you interact with your application. In recent versions, the codegen UI also has more features, like the ability to add assertions and capture an ARAI snapshot.
I'm also more and more interested in AI and how it can help me in my daily work. While it didn't convince me at first, the GitHub Copilot agent mode and the Model Context Protocol (MCP) have changed my mind. I find these two features very interesting and something I want to explore more because I believe they can help me to be more productive.
I really like this Visual Guide To MCP Ecosystem of what MCP is by Ebony Louis, in which she uses James Bond as an analogy. Give it a read!
Because of my recent interest in AI, and my passion for Playwright, I wanted to combine the two and see how they work together. I'm curious about the AI capabilities that Playwright has to offer and want to test if it can help me write tests for an application.
Some criteria I have in mind to evaluate the AI capabilities of Playwright are:
- Are the tests relevant?
- How good or bad is the quality of the test?
- Are the tests green on the first run?
- How's the process of using AI to write a Playwright test, is it easy to prompt?
To write a good test we need to have a good understanding of the application we want to test (this is the context). Previously, it was difficult to provide context to the AI, but with the introduction of the Model Context Protocol (MCP) and the Playwright MCP server, this is now possible. At least, that's what I want to find out.
For this PoC, I will use my blog as the application to test.
Installing the Playwright MCP
Add the following settings to your VSCode's settings.json file to install the Playwright MCP.
The server installs the Playwright MCP through npm, so make sure you have it installed on your machine.
After that, you should see the Playwright MCP tools in the list of available tools.
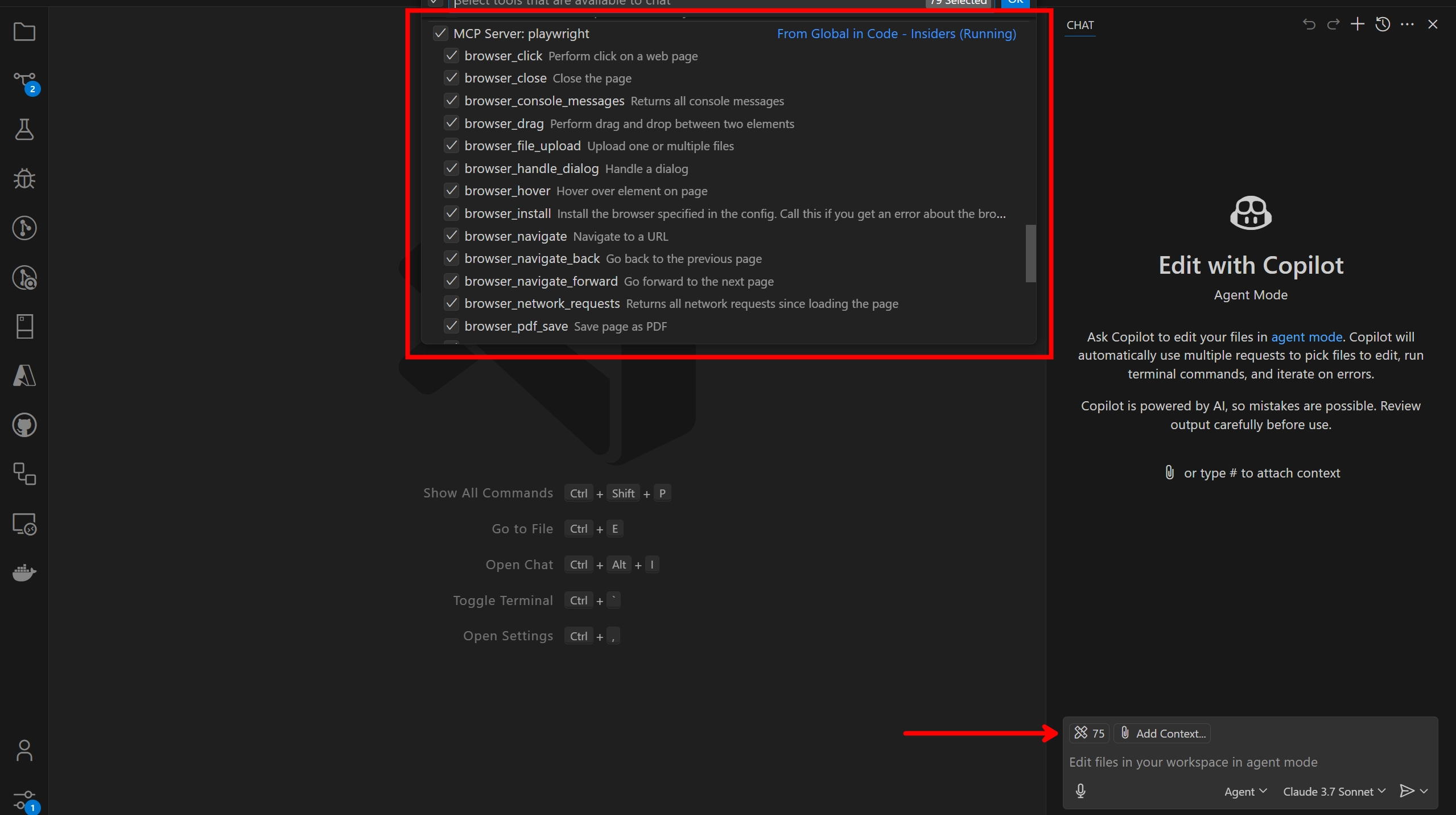
This allows you to run certain playwright commands via GitHub Copilot's agent mode. To run the commands, use the hashtag (#) prefix in your prompt.
The Playwright commands all start with browser_, followed by the command you want to run. The most important command in the context of this blog post is the one to navigate to a webpage, which is #browser_navigate.
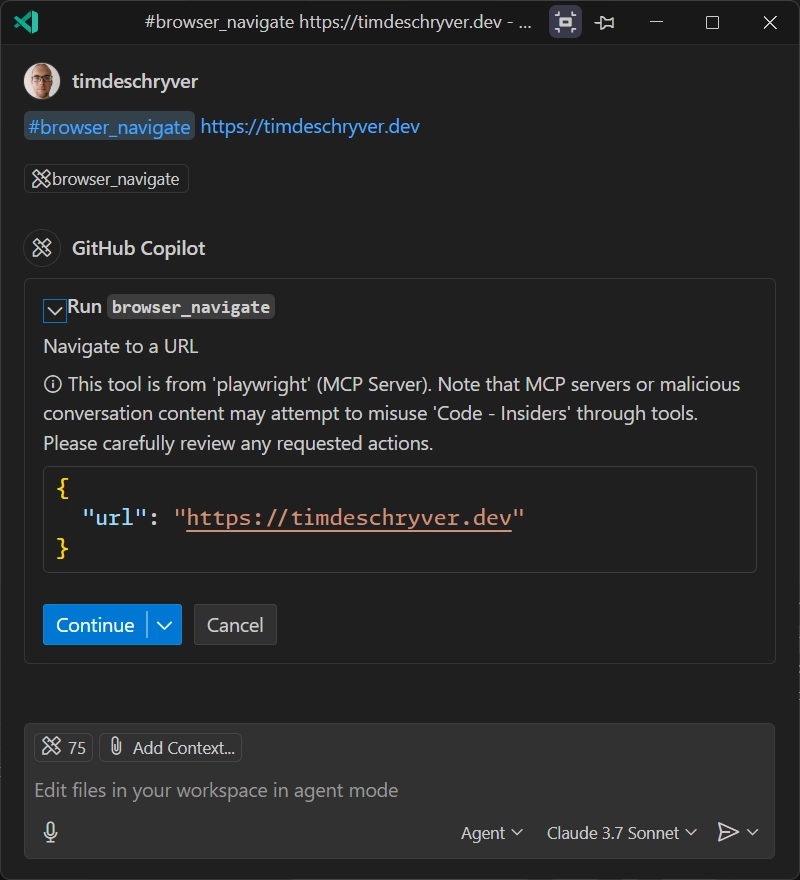
To try it out, open a new chat in the Copilot chat and type the following command:
After running the command, you are asked for permission to run the command.
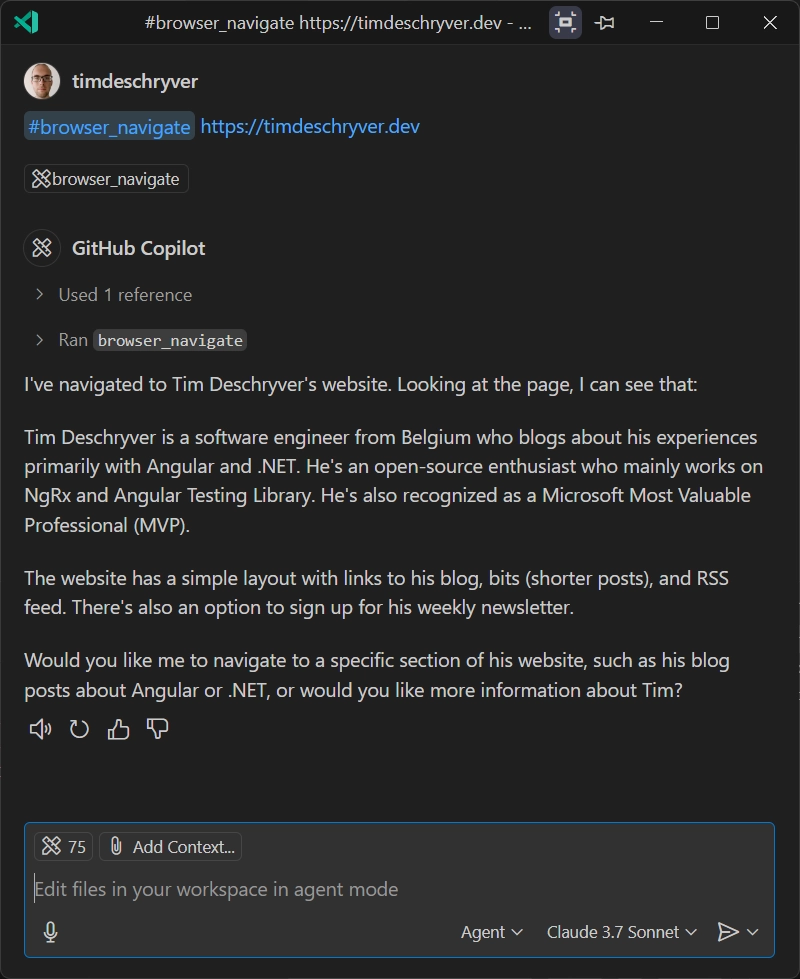
After you permit to the agent, it executes the command, resulting in a browser window that opens the page. For this simple prompt, it gives a summary of the page.
Vibe coding a test
So far, this is nothing special, as you could also reference the same page in your prompt and ask for a summary.
But, the real power is that it's now possible to let the agent interact with the page and perform user actions, like clicking buttons, filling out forms, and even validating the results of those actions. Previously, I also had rare occasions where I couldn't fetch the page (e.g. using the #fetch tool) because the page required authentication, or required JavaScript to be executed. This becomes possible now with the Playwright MCP server.
Let's try it out more and ask the agent to write a test for the blog page of my blog using Playwright. The blog page displays a list of blog posts and has a search input to filter the posts, which can be used with a search text or by clicking on a tag.
The prompt I used is the most basic one I could think of and simply asks the agent to write a test for the blog page using the #browser_navigate tool.
While the agent interacts with the page, it can also ask more permissions to run commands, like clicking on a button or filling out a form.
After Copilot is finished, I notice that a new blog.test.ts file is created in the tests folder.
In the chat, I can also see the progress of the agent while it writes the test, and the functionalities it detected on the page.
Here's a trimmed-down excerpt of the output.
By simply looking at the output, I was already impressed and confident that the test would be relevant. Now, the question is, how's the quality of the test cases?
The test code
The tests that are generated (with Claude 3.7) are the following:
- loads the blog page with articles
- searches for articles
- filters blog posts by tags
- opens and reads a blog post
- checks TLDR functionality when available
To not go through all tests, let's scope into the ones that are the most important to me, being the ones that open a blog post and the one that verifies the search functionality. Looking at the different two cases should give us a good idea of the quality of the tests that are generated by the agent.
The test to open a blog post is the simplest one. It navigates to the blog page, gets the first article's title, clicks on the "Read more" link, and verifies that the article page is opened and that the title is displayed. There's nothing fancy about this, but it does the job.
Looking at the test, I can see that it uses the getByRole method to get the elements on the page, which is a good practice. It also uses the toBeVisible assertion, which is preferred over isVisible because it waits for the element to be visible and retries this until the element is visible, or until it timeouts. This is a good practice, as it makes the test more reliable. If I were to write this test, I would have ended up with a similar test, so I think the quality is good.
The second test is the one that verifies the search functionality. This test is a bit more complex, as it needs to interact with the search input and verify that the results are filtered correctly. It looks like this:
Again, the test looks good to me. I also like it that it compares the count before and after the filter, and that it verifies that the search term is present in the first article. This is a good way to verify that the filtering actually works. The only thing I don't like is that it verifies that the first article is visible, which is not really necessary, and is a duplicate assertion.
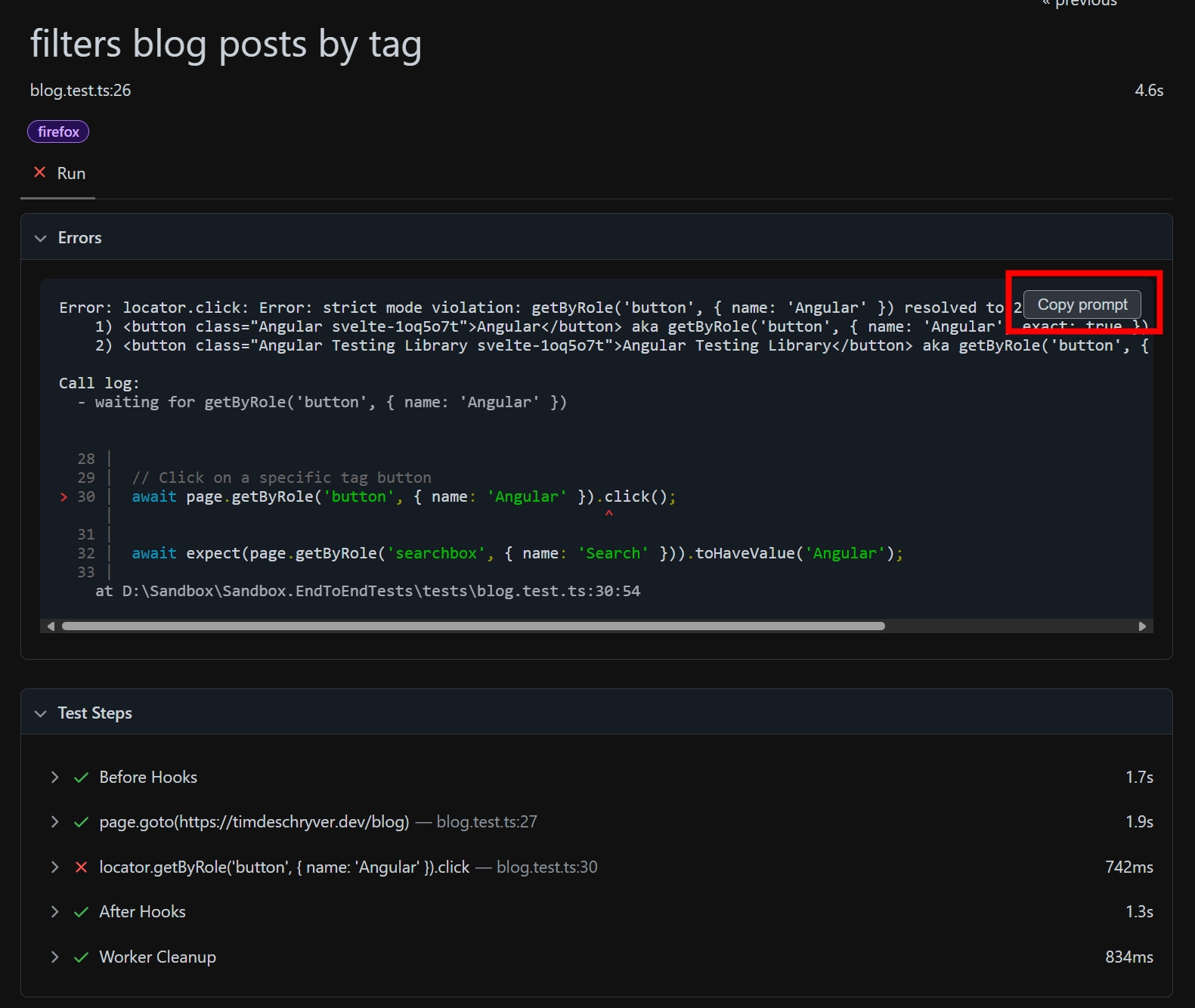
When running the test suite, these tests turned green on the first run. But, the other tests that were generated, like the one that filters by tags, are currently failing.
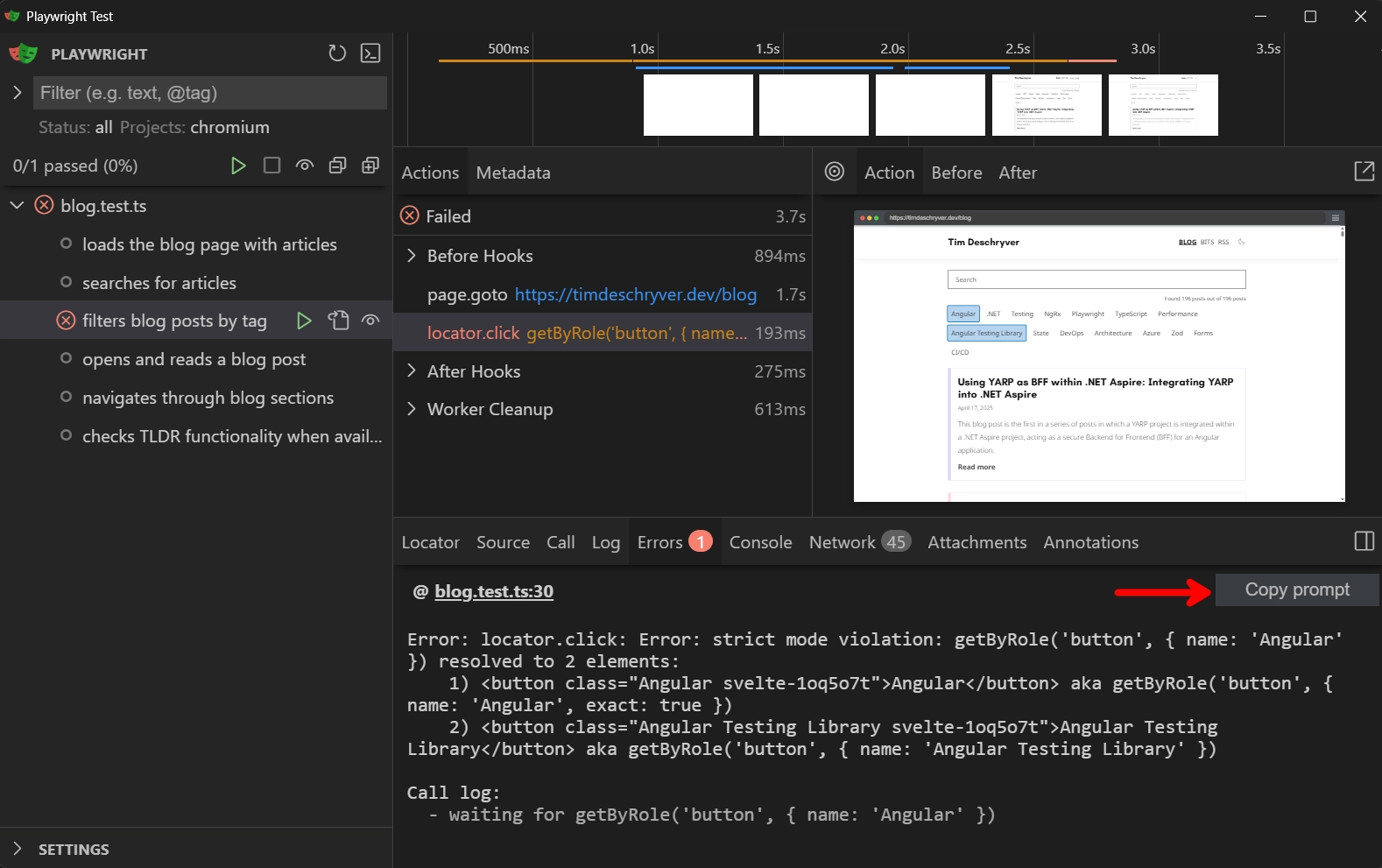
By looking at the failing test, can you spot the problem? Of course this is hard, so let me help you by providing you the failure message.
When we read the error message, we can see that the test is failing because it can't find a unique button with the name "Angular". If you're not familiar with Playwright, this can be a problem that is hard to solve, for which you will probably need to look at the documentation or search for the solution online. The same applies to harder problems.
Copy as prompt
As usual, the Playwright team is always thinking about the developer experience and how to improve it. For this problem, the team has added a feature to copy the error message as a prompt. This allows you to copy the error message and paste it in the chat, in order for the agent to try to solve the problem for you.
You can find this "copy as prompt" button in two ways.
- In the UI mode (while running
npx playwright test --ui) it's located in the "Error" tab.
- Within the reports, it's located on the details page of the test that failed.
When you click on the button, it copies the prompt to your clipboard, which can directly be pasted into the Copilot chat window. The prompt contains some basic instructions, the error message containing the stack trace, an ARIA snapshot of the page, and the test source code.
When I pasted the prompt in the chat, I got a response that explained the problem, why this occurs, and provided a solution. When it solved the problem, Copilot also wanted to run the test to verify that the solution fixed the test.
If you're wondering, the solution was to use the exact option to make sure that only one button is selected.
Conclusion
In this blog post, I wanted to explore the AI capabilities of Playwright and how it can help me to write tests for my application.
My first impression is that this is promising. The tests that are generated are relevant and of good quality. It's not perfect, but it's a good start. For example, I would like to have more assertions in the tests, like verifying that the search input contains the correct search term after clicking on a tag. But, this is something that can easily be added by us when we review the tests.
The examples of this blog post are performed in an empty project. When using this technique in a real project, the agent uses the source code to understand the context better and thus also generate better tests. It also makes use of team standards when generating the tests, e.g. it can detect ESLint warnings and errors of ESLint Plugin Playwright and update the code accordingly.
I can see that this is a great way to start introducing tests in a project or to get a head start when writing tests for a new feature. It can also be a gentle way to get to learn Playwright and how to write tests with it.
Feel free to update this blog post on GitHub, thanks in advance!
Join My Newsletter (WIP)
Join my weekly newsletter to receive my latest blog posts and bits, directly in your inbox.
Support me
I appreciate it if you would support me if have you enjoyed this post and found it useful, thank you in advance.
