How to make your Azure DevOps CI/CD pipeline faster


Our team uses a monorepo that includes 20 projects. All of these projects need to be build and deployed (to two different environments) with every merged Pull Request. Besides our projects, we also include another 10 artifacts from other teams during a deploy. Currently, this isn't fast. Despite that all the steps of a stage are run in parallel, it still takes a full hour to run our CI/CD pipeline.
- the build stage of our projects take between 10 and 15 minutes
- the deploy stage to a test environment (hosted on a Virtual Machine) lasts between the 15 and 20 minutes
- the test stage (end-to-end and integration tests in parallel) takes another 20 to 25 minutes
- the second deploy stage to a QA environment (hosted on a Virtual Machine) takes up another 15 and 20 minutes
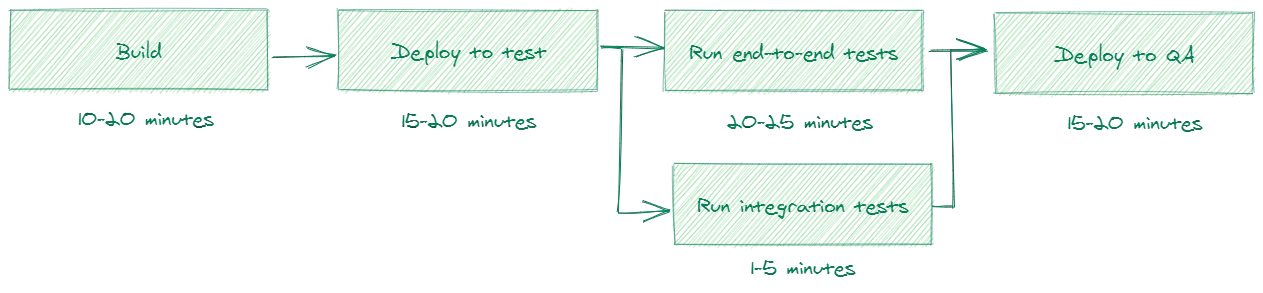
This isn't ideal and results in wasted time and some frustration in our team.
If we take a closer into the different stages, we see that:
- there's one project during the build stage that consistently runs for 10 minutes
- deploying one project is fast, but because of the number of projects that need to be deployed it takes a long time
- the integration tests are fast, while the end-to-end tests are slowing down the test stage
With these observations in mind, we can see that culprit is one slow build and the number of projects that need to be deployed.
Note: we tried to use multiple deploy agents on the server, but for some reason, this resulted in many errors during the deploy stage. Most of the time there was always one project where the deploy failed with the vague error
the process is already in use.
We recently upgraded our servers, and while it helped to speed up the build stage, it surely didn't have the desired effect we were hoping for. Because all of the steps run in parallel we couldn't improve the pipeline speed this way either.
So if we can't work harder, we must work smarter.
With the inspiration of NX, the solution to a faster CI/CD pipeline is to only build and deploy the projects that are affected in the last commit.
So how do we accomplish this within an Azure DevOps pipeline?
Finding affected projects
To detect projects that are modified we created a new stage ProjectMarker, which will be the first stage of the pipeline.
The ProjectMarker stage creates a new environment variable AffectedProjects that can be used in the next stages to determine if a project needs to build and deployed. (Side note: if you're not using stages in your pipeline, this idea will still work but the syntax to read the AffectedProjects environment is different.)
The ProjectMarker stage just has a single job Mark that contains a single step Marker.
The Marker step runs a NodeJS script with the $(Build.Reason) and the $(Build.SourceBranch) predefined variables as arguments.
The source code of the affected-projects-marker script looks as follows.
We're not going into details of the script, but you can take a look at it, and then we'll go over the idea behind it together.
While the script is written in JavaScript, it can be rewritten in any language. The most important thing in the script is to determine what projects are modified within the last commit and to assign these modified projects to an environment variable. I commented all steps along the way, so it should be possible to rewrite the script.
In the affected-projects-marker.js script we use the git diff command git diff HEAD HEAD~ --name-only to get all of the paths of files that are modified. When we have that information, we can then map it to a project.
In the affected-projects-marker.js script we also have a dependency "graph" because one project could affect another project.
Once all affected projects are known, we create a new environment variable AffectedProjects and assign all the affected projects to the AffectedProjects variable. With this variable, we can make successive jobs smarter.
Let's take a look at an example:
If the last commit includes a change to the shopping cart feature, the git diff command might look like this:
Because the commit includes a change to the AddToCart.cs file of the BackendProject01 project, BackendProject01 will be marked as affected.
In the script, we also defined that BackendProject01 has a dependency on FrontendProject01.
Thus, because BackendProject01 is affected, the project FrontendProject01 is also added to the affected projects.
As a result of the commit, the AffectedProjects environment variable has the value BackendProject01;FrontendProject01.
Build affected projects
To only build the projects that are affected, we use the AffectedProjects environment variable inside a condition.
To access the AffectedProjects environment variable in the next stages, use the name of the stage, job, and task.
In our case this means we can access the AffectedProjects environment variable with stageDependencies.ProjectMarker.Mark.outputs['Marker.AffectedProjects']:
ProjectMarkeris the name of the first stageMarkis the name of the job in the first stageMarkeris the name of the task that executes theaffected-projects-marker.jsscript
It's important that stages who want to use a custom-defined environment variable of another stage, explicitly add the stage (in which the environment variable is defined in) to the dependsOn property of the stage that wants to use the environment variable.
We have to do this because by default a stage can only access environment variables from its previous stage.
In our case, this means that we need to add a dependency to the ProjectMarker stage to stages that want to make use of the AffectedProjects variable. Next, we can use the environment variable inside a condition to run or skip a job.
Deploy affected projects
For the deploy stage, we can use the same technique.
- Create a new
Deploystage - Add a dependency on the
ProjectMarkerstage - Add a condition to the job to check if the job's project is added to the
AffectedProjectsenvironment variable
This gives us the following flow of the refactored pipeline:

Only run affected Cypress tests
A few weeks after I wrote this blog post, I encountered the blog post, Test grepping in Cypress using Module API, written by Filip Hric. In this post, Filip explains how to run specific Cypress tests by using the cypress.run() method.
Based on his knowledge, I changed the default cypress run command to a custom implementation that only runs the affected tests based on the Marker.AffectedProjects variable that we set in the release pipeline.
I came up with the following script that maps affected projects to the Cypress tests. The Cypress test are grouped per feature in a directory.
The yaml file to run the Cypress tests is straightforward, we use the np, task to run the run-affected-cypress-tests.js script and we pass it the affected projects as an argument.
Conclusion
The trick to making your CI/CD pipeline faster is to lower the amount of work. By only building and deploying the projects that are modified, we save a lot of time.
In the worst-case scenario, we still have to wait 10 minutes during the build stage when that one slow project is affected. But this only happens sporadically. When that slow project isn't included, the build stage now only takes 2 minutes on average and sometimes it even takes just a few seconds.
The two deployment stages are now more consistent. A commit usually affects 2 projects, making the deploy stage run in 1 minute on average.
Besides the time saved to run the pipeline, this technique also consumes fewer resources. This has the advantage that:
- other pipelines don't need to wait until a build or release agent is free
- it's cheaper (and more effective) in comparison to upgrading servers to speed up your builds
- a deploy is more reliable and is causing fewer errors than before
Yes, occasionally when all of the projects are affected, we still have to wait an hour but 90% of the time this won't be the case.
Because we made our CI/CD pipeline smarter, we've shortened the feedback loop from a merged Pull Request, to a new deploy to our QA environment. We don't waste time, and more importantly, the developers are happy.
The time that's invested into making your Azure DevOps pipeline smarter, by adding these checks, quickly repays itself after just a couple of runs.
The end result
Our latest run, with affected 2 projects, took 23 minutes in total, which is more than 50% faster than the original run:
- 5 seconds for the stage to mark the projects as affected
- 1.5 minutes to build the projects
- 50 seconds for the deployment to the test environment
- 20 minutes spend into testing our environment
- 1 minute for the second deploy stage to a QA environment

As you can see, the test stage takes up most of the time, 20 minutes, or 85% of the total time. We could try to make this stage smarter and only run certain tests, but this will take more time to implement and to maintain. I also don't want to cut into these end-to-end tests because they prevent regression and they make sure that our software is working.
With the modified test stage (Only run affected Cypress tests), we managed to spare another 14 minutes.
Incoming links
Feel free to update this blog post on GitHub, thanks in advance!
Join My Newsletter (WIP)
Join my weekly newsletter to receive my latest blog posts and bits, directly in your inbox.
Support me
I appreciate it if you would support me if have you enjoyed this post and found it useful, thank you in advance.
